- Published on
2026数字中国创新大赛初赛wp之大批量文件处理
- Authors

- Name
- 弈秋
2026数字中国创新大赛初赛wp之大批量文件处理.md
缘起
其实这题目蛮简单的,就是在word中藏了信息,新格式的word(.docx)已经基于xml和zip了,其实没什么可藏的,唯一的难点是数量。
题目

附件我放在了网盘:
https://cloud.189.cn/t/imamemJ3yuqi(访问码:b09i)
思路
解压文件看看,其实很简单,就是word而已,202个,每个打开看看:
- 一全选看看是不是字体颜色白色隐藏

- 打开word的隐藏选项
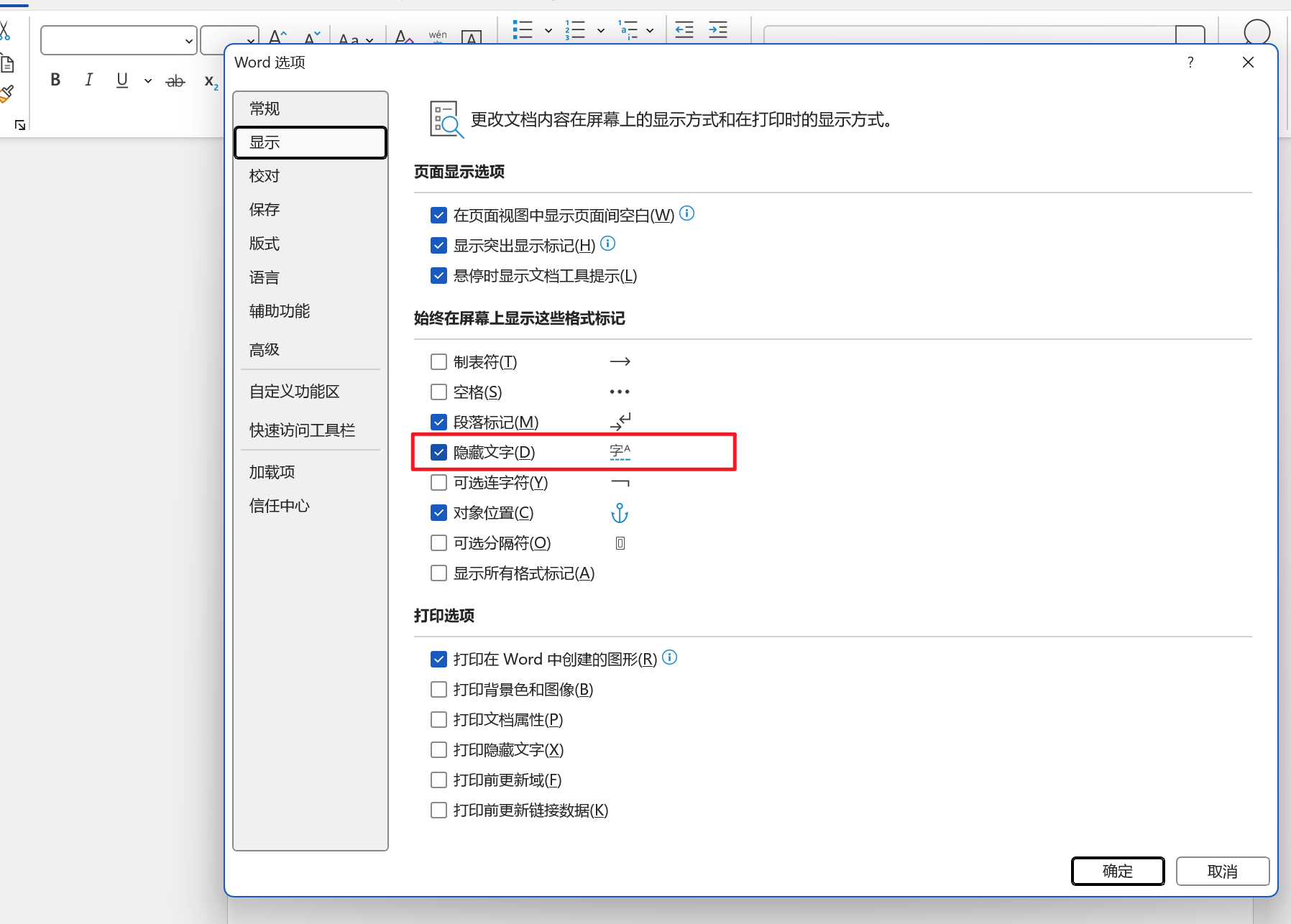
然后,重复202次...
很明显,这是不可能的,这题还没做完,比赛就结束了,只能靠脚本。
老规矩,上代码:
import re
import zipfile
from pathlib import Path
from xml.etree import ElementTree as ET
# 1
def extract_text_from_docx(docx_path):
text = ""
try:
with zipfile.ZipFile(docx_path) as docx_zip:
with docx_zip.open('word/document.xml') as document_xml:
tree = ET.parse(document_xml)
root = tree.getroot()
for elem in root.iter():
if elem.tag.endswith('}t'):
text += elem.text + ' '
except Exception as e:
print(f"Error processing {docx_path}: {e}")
return text.strip()
# 2
def find_idcards(text: str) -> list:
results = []
pattern_18 = r'\b(\d{17}[\dXx])\b'
for match in re.finditer(pattern_18, text):
id_num = match.group(1)
if id_num not in results:
results.append(id_num)
return results
if __name__ == '__main__':
all_results = []
docx_files = list(Path("./docs").rglob('*.docx'))
total = len(docx_files)
print(f"找到 {total} 个 Word 文档")
idcard = []
for i, filepath in enumerate(docx_files, 1):
text = extract_text_from_docx(filepath)
idcards = find_idcards(text)
if len(idcards) > 0:
print(f"[{i}/{total}] 扫描: {filepath.name} - 发现 {len(idcards)} 个身份证号")
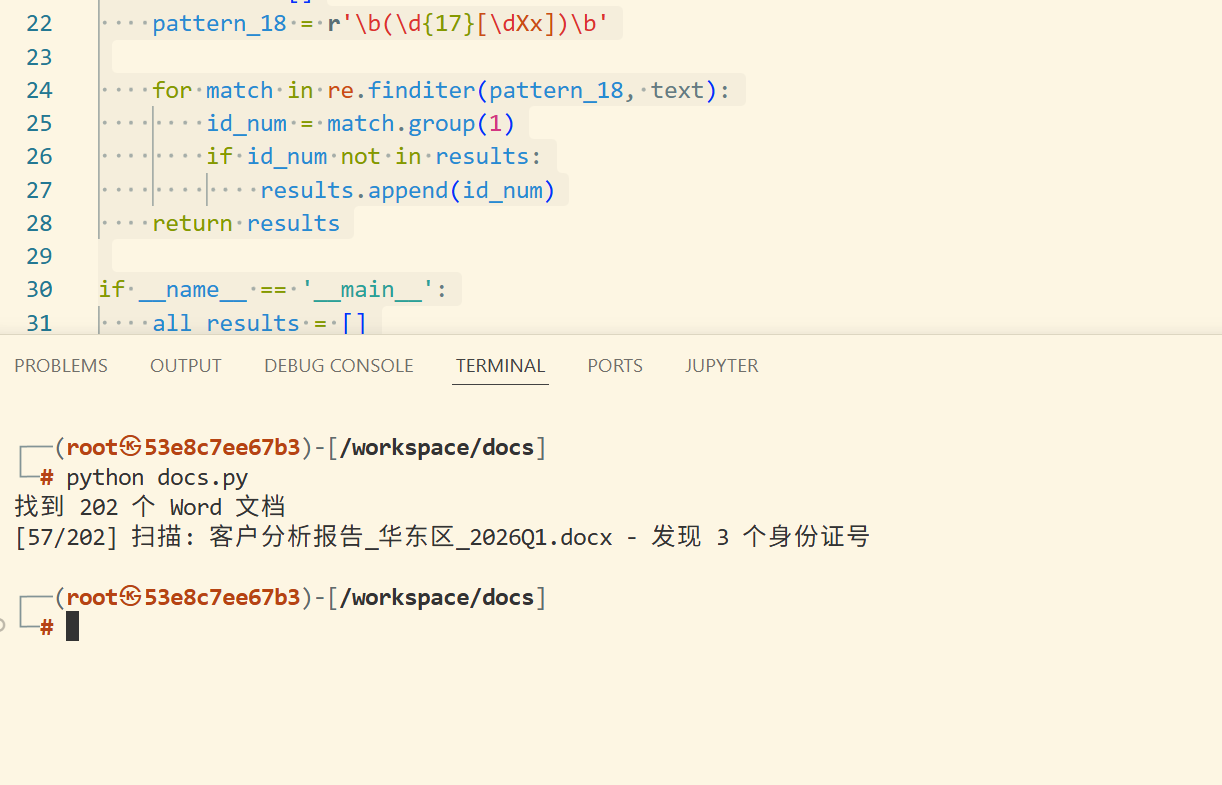
跑一下结果:
简单解释:
这是一个简单的抽取word纯文本的简单方式
这个是一个最简单的判断身份证的方式:
其实这里注意2点:
1、身份证分老旧(15位、18位)
2、表现格式:就是一串连续的数字,还是分段存储的(可能是空格、短横等等)
不过比赛么,为了节省时间,就不用写那么全年的脚本,一个一个试就好了,先试18位的,一次就中了
小结
自动CTF比赛分裂成网安和数安以来,数安越来越有自己的特色了,越来越多的题目都是靠量来增加难度的,这其实也更贴实际使用。
推荐阅读
本次比赛其他题目: